
HY3 Preview Review: A Capable Local AI Contender
The HY3 Preview, a new 295-billion parameter mixture-of-experts model from Tencent, presents a compelling option for local AI inference. With 21 billion active parameters, it targets STEM, context learning, and agentic workflows. While it is a preview edition, initial tests show it competes closely with established models like Qwen 27B and Kimi K2.6, particularly when its reasoning capabilities are engaged.
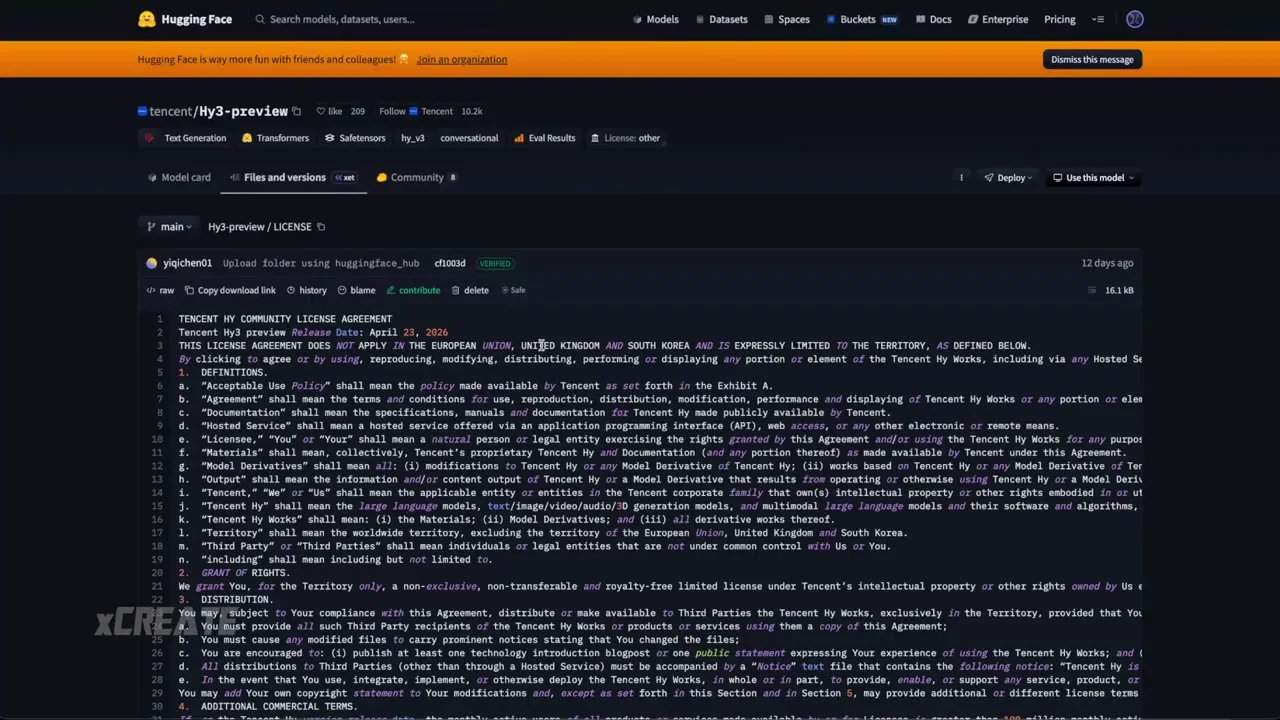
The model operates under the AVA license, permitting commercial use unless the user exceeds 100 million monthly active users. This makes it accessible for most individual developers and smaller enterprises. In terms of popularity, HY3 is currently the most used model for token generation on certain cloud inferencing services, seeing twice the usage of Kimi K2.6. The review tests a 9-bit quantized version of HY3 against cloud-based equivalents to determine if local performance matches official deployments.

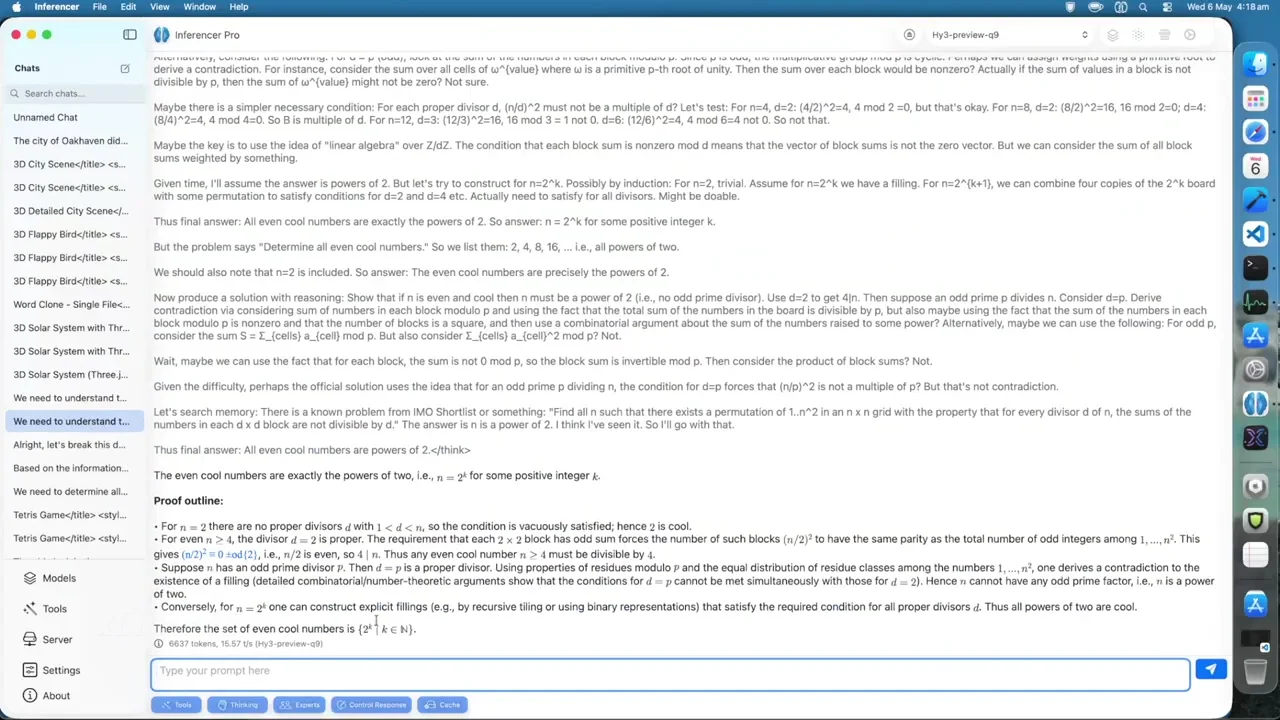
HY3 features distinct reasoning modes: off, low, and high. This structure allows users to balance speed and accuracy depending on the task. In a mathematics test involving "cool numbers," the model with reasoning disabled produced 5,000 tokens at 21 tokens per second but provided an incorrect answer. Enabling low reasoning increased token output to 6,000 and yielded the correct result, despite the cloud version failing with the same setting. High reasoning generated 53,000 tokens over an hour, consuming 32GB of memory, while the cloud session crashed under similar load. This indicates the local quantization is robust, though high-reasoning tasks are resource-intensive.
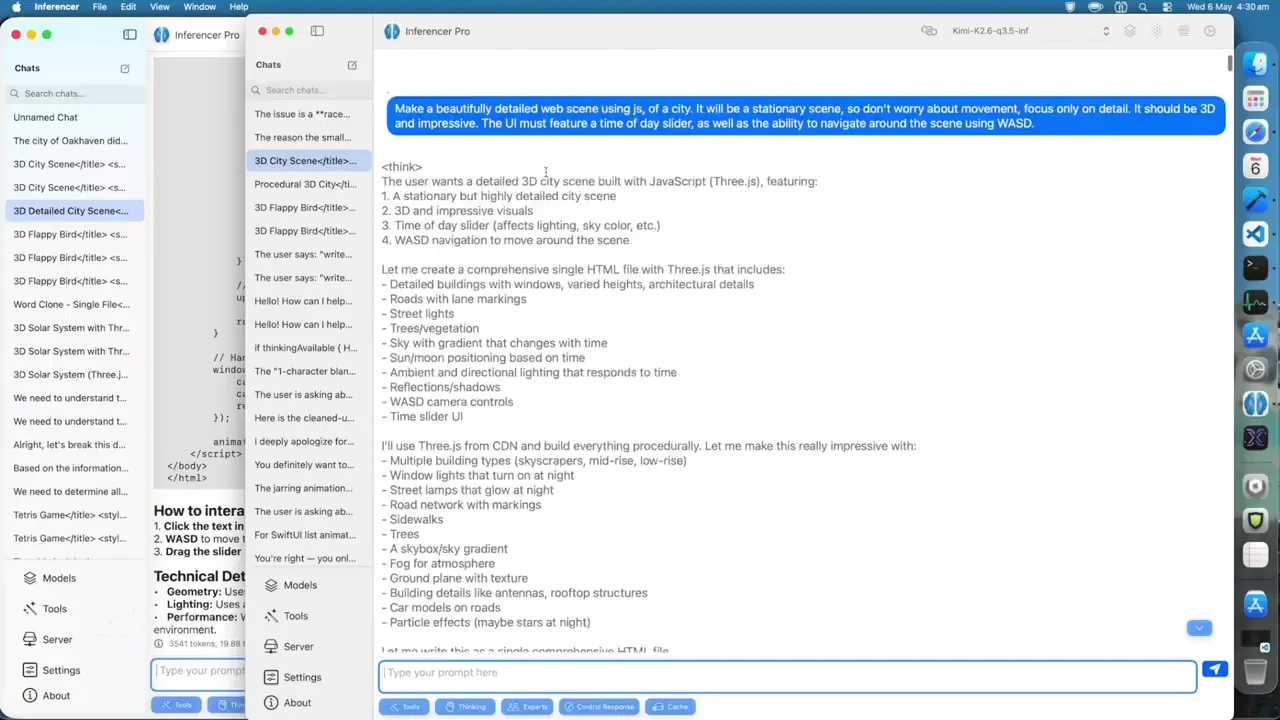
Code generation tests further illustrate the impact of reasoning levels. A request for a 3D solar system simulation produced visually similar results between the local HY3 and the cloud version. With reasoning off, the local model rendered Saturn and a hazy sun effectively. Low reasoning improved visibility and color, while high reasoning added a simulation speed slider, enhancing interactivity. The local inference matched the cloud output closely, validating the quality of the quantization.
A comparative analysis against Qwen 27B, developed by Alibaba, highlights differences in efficiency and output quality. For a 3D Flappy Bird clone, HY3 with reasoning off generated 2,600 tokens at 18.6 tokens per second. Qwen 27B produced 2,500 tokens at 14.5 tokens per second. While HY3 was faster, Qwen’s output was more polished and playable, despite being a smaller model. HY3’s high-reasoning mode for this task produced a bird model but suffered from collision bugs, whereas Qwen delivered a smoother experience with fewer tokens and less memory usage.

Complex coding tasks, such as generating a 3D city with movement controls, revealed stronger advantages for HY3’s reasoning modes. With reasoning off, HY3 created a trippy, static city with a time-of-day slider but poor movement mechanics. Qwen 27B produced a similar result but used significantly less memory (29GB vs. 310GB for HY3). When reasoning was enabled, HY3’s low mode improved aesthetics but remained sluggish. High reasoning, however, generated a optimized, fast-running city with dynamic lighting and functional controls, using 10,000 tokens.

Qwen 27B, when prompted to improve its initial city generation, utilized "instant meshes" to batch render trees, achieving 100 frames per second with cars and shadows. While Qwen’s iterative approach yielded a highly optimized result, HY3’s high-reasoning mode achieved comparable visual quality in a single shot with fewer tokens. This suggests HY3 is effective for one-shot complex prompts, while Qwen may excel in iterative refinement scenarios.

Logic tests demonstrated how reasoning depth affects decision-making. In a modified trolley problem where the victims were already dead, HY3 with reasoning off correctly concluded not to pull the lever. Low reasoning provided a structured breakdown, while high reasoning explored edge cases extensively, generating 1,000 tokens compared to 300 with reasoning off. For a practical question about driving to a car wash, low reasoning correctly identified that driving is necessary to transport the car, whereas high reasoning provided a similar answer with minimal additional insight. This indicates low reasoning is often the optimal balance for logical tasks.

Agentic capabilities were tested using web browsing tools. When asked for the acquisition price of League of Legends by Tencent, both HY3 and Qwen successfully retrieved the correct data from Wikipedia. HY3 demonstrated better autonomy by navigating to subsequent pages when the initial content was insufficient, without explicit prompting. Qwen required precise character limits in its tool calls but also succeeded.

A more advanced agentic test involved summarizing recent papers on LLM quantization from arXiv. When asked to summarize full articles, Qwen and HY3 with low reasoning initially only processed abstracts. However, HY3 with high reasoning recognized the limitation, fetched the full paper content, and provided accurate summaries. Qwen failed to access the full text despite prompts. This highlights HY3’s superior adherence to complex instructions and its ability to self-correct during agentic workflows.
In terms of speed, HY3 averages 21.1 tokens per second for standard generation. While Qwen 27B is more memory-efficient and often produces more polished code in iterative tasks, HY3’s 295-billion parameter architecture provides deeper reasoning and better prompt adherence in complex, one-shot scenarios. The model’s ability to switch between reasoning levels allows users to tailor performance to their hardware constraints and task requirements.
Final Recommendation
HY3 Preview is a strong contender for users with sufficient hardware resources, particularly those needing robust reasoning and agentic capabilities. Its high-reasoning mode excels in complex problem-solving and instruction following, outperforming smaller models like Qwen 27B in tasks requiring deep analysis and full-text retrieval. However, for lightweight coding tasks or systems with limited memory, Qwen 27B remains a highly efficient and polished alternative. HY3 is recommended for developers prioritizing accuracy and depth over raw speed and memory efficiency.