
Ultimate Battle! Gpt 5.5 vs Opus 4.7 | Who will Win?
OpenAI’s GPT 5.5 and Anthropic’s Opus 4.7 face off in a comprehensive comparison of agentic coding, design, and physics simulation capabilities. The review highlights a clear divergence in strengths: Opus 4.7 excels in front-end aesthetics and visual fidelity, while GPT 5.5 demonstrates superior logic, physics implementation, and algorithmic reasoning. The final score favors Opus 4.7 with six points to GPT 5.5’s five, though the margin is narrow.
Pricing and Setup▶ 0:00
GPT 5.5 introduces a price increase that exceeds Opus 4.7’s existing rates. GPT 5.5 costs 5 per million input tokens and30 per million output tokens. Opus 4.7 charges 5 per million input tokens and25 per million output tokens. Both models are tested at medium reasoning effort, which OpenAI recommends for token efficiency. The evaluation uses agentic prompts that require end-to-end task completion, including web searching, API integration, and code generation.
Test 1: Website Generation for "Orange"▶ 1:40
The first task requires generating a complete website for a fictional consumer technology brand named "Orange." The prompt mandates the use of a Gemini API key for text-to-image and video generation, requiring the models to fetch assets, structure them, and implement scroll-based animations.
Opus 4.7 produces a visually polished site with smooth scroll animations and a cohesive design language. The product configuration section allows users to change phone colors with gradual gradient shifts rather than abrupt changes. However, the scrolling mechanism occasionally gets stuck, and some product sections remain hidden. GPT 5.5 generates a functional site but reuses images across different product categories, such as using a laptop image for a tablet. The visual quality of the generated assets is lower, and the overall layout lacks the refinement of Opus 4.7. Opus 4.7 wins this round due to superior aesthetic execution.
Test 2: Educational Video on Turbofan Engines▶ 16:40
This test challenges the models to create an educational video about turbofan jet engines. The task involves generating text, converting it to speech via Gemini’s TTS, creating background music, and rendering code-based animations for each frame.
Opus 4.7 creates a dynamic video with zooming and panning animations that highlight specific engine components like the fan, compressor, and combustor. The narration is synchronized well, and the visual progression effectively explains the high-bypass ratio concept.

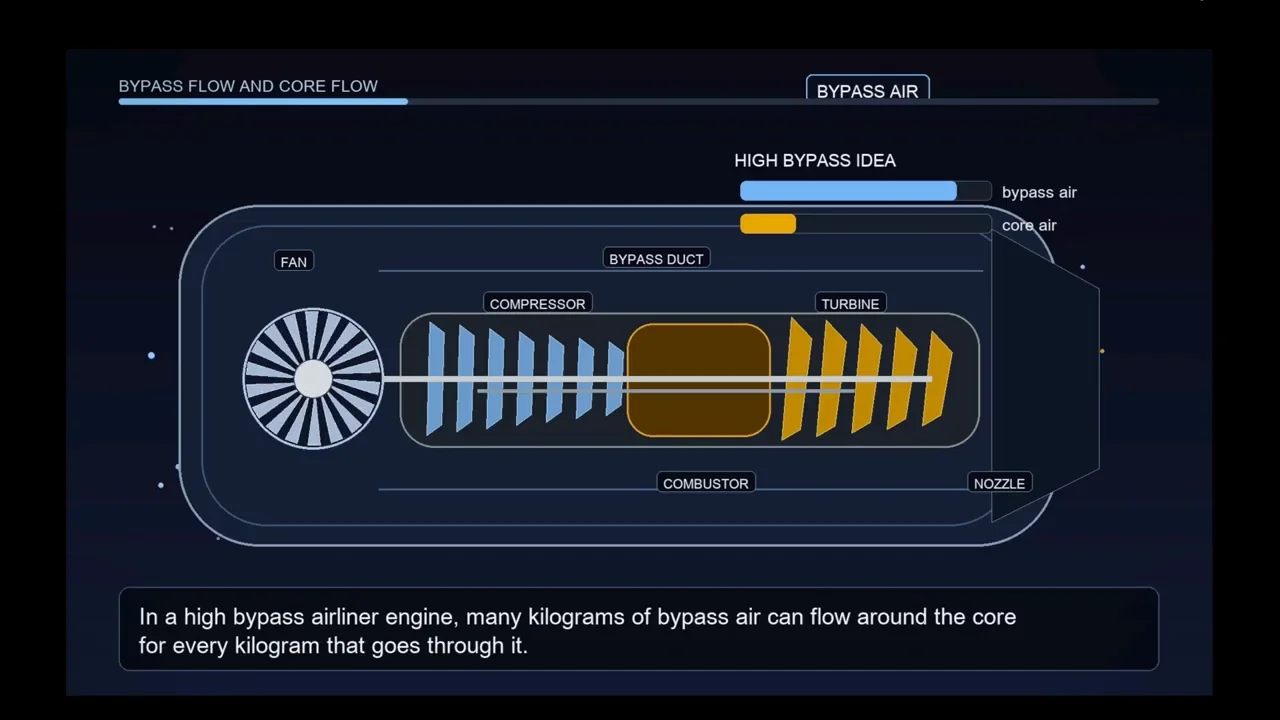
GPT 5.5 produces a video with static, basic 2D animations. The visual representation is less engaging, lacking the depth and camera movement seen in Opus 4.7’s output. While the narration is accurate, the visual component is rudimentary. Opus 4.7 wins for creating a more entertaining and visually detailed educational asset.
Test 3: Watch Website Replica▶ 31:40
The models must replicate a luxury watch website from a provided mock-up. This test evaluates front-end precision and attention to detail.
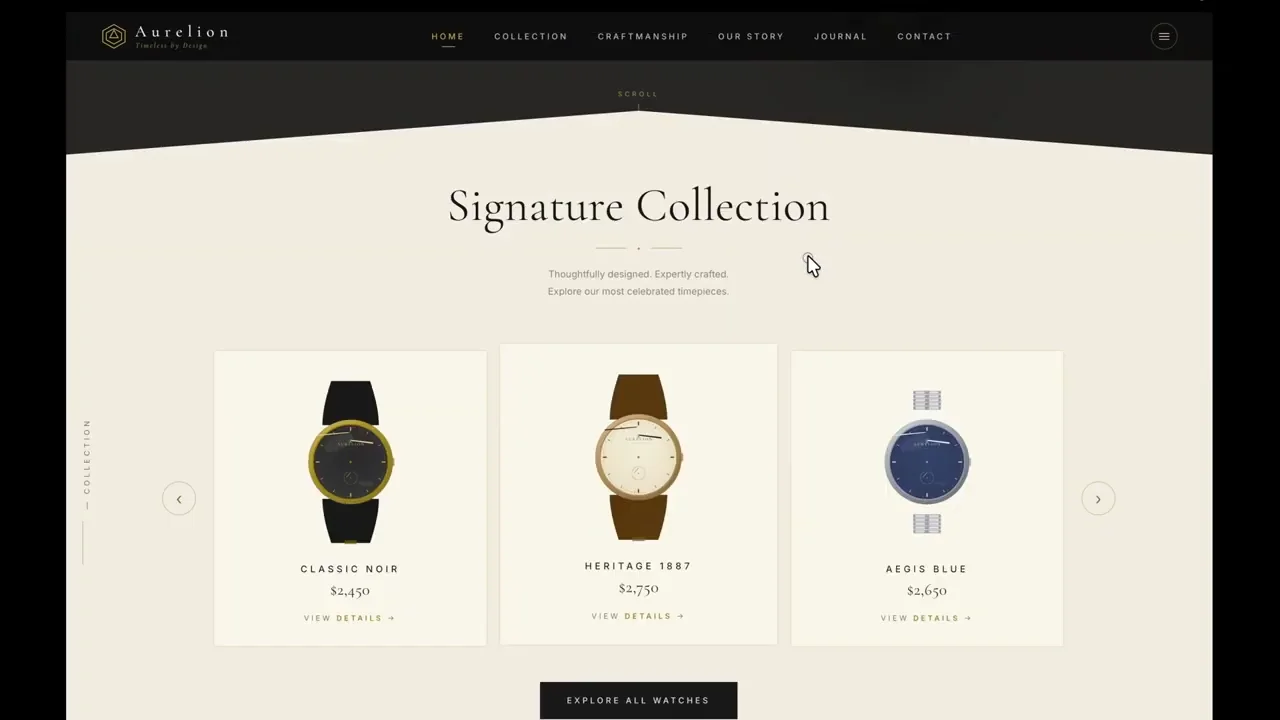
Opus 4.7 generates watches that closely resemble the reference images, with accurate strap textures and dial layouts. The triangular section headers match the design brief. Minor issues include misaligned minute hands and incorrect gear icons. GPT 5.5 struggles with visual fidelity. The watches appear generic, and the second hands are implemented incorrectly. Text overlays obstruct the watch faces, and the mechanical animations are chaotic rather than precise. Opus 4.7 wins due to higher fidelity to the source material.

Test 4: Hill Climb Racing Game▶ 35:00
This task involves creating a physics-based hill climb racing game. Stability and suspension mechanics are the primary evaluation criteria.
Opus 4.7’s initial attempt results in a vehicle that crashes immediately due to poor physics calculations. Even after updates, the vehicle remains unstable and difficult to control. GPT 5.5 produces a more stable vehicle with functional suspension. Although the movement is slow, the car does not crash arbitrarily, and the user can control its balance. GPT 5.5 wins for delivering a playable mechanic.
Test 5: Need for Speed-Style Racing▶ 40:00
The models are asked to build a 3D car racing game. Opus 4.7 fails significantly, with vehicles moving backward, spawning off-track, and clipping through the ground. GPT 5.5 generates a functional game with working physics and opponent AI. The steering controls are inverted, but the core gameplay loop is intact. GPT 5.5 wins for providing a working prototype.
Test 6: iPhone Fold Landing Page▶ 40:00
This test requires a high-fidelity 3D product page for a fictional foldable iPhone. The prompt specifies that both inner and outer displays must be visible and active.
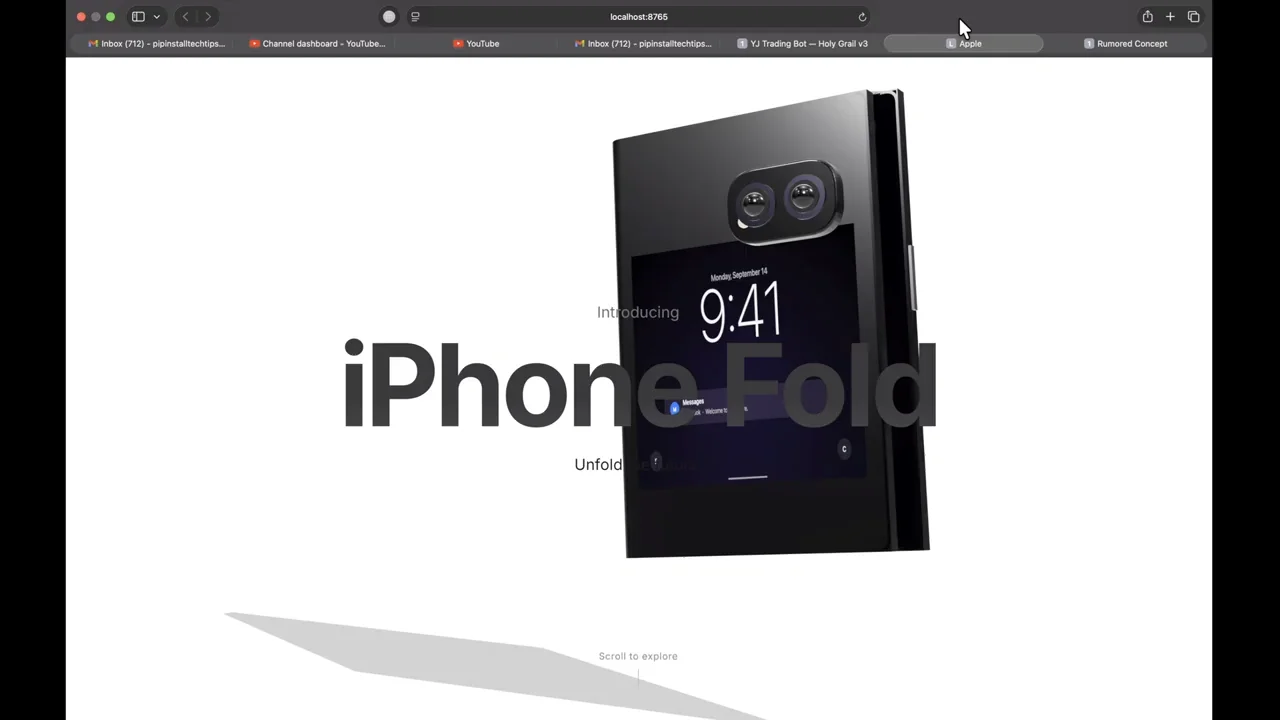
Opus 4.7 creates a detailed 3D model that rotates smoothly. However, it fails to render the displays as active screens, showing them as static slabs. GPT 5.5 attempts to show the displays but suffers from significant graphical glitching during the folding animation. Both models fail to meet the core requirement perfectly, but Opus 4.7’s 3D modeling is slightly more refined. The round is considered a near-tie, with a slight edge to Opus 4.7 for visual quality.
Test 7: Bizarre Business Logo▶ 50:00
The task is to design a logo for a luxury spa serving heavy machinery. Opus 4.7 generates "Titan Time," featuring a lotus and machinery elements that are visually coherent. GPT 5.5 creates "Iron Lotus," but the logo is abstract and difficult to interpret. Opus 4.7 wins for clearer conceptual execution.
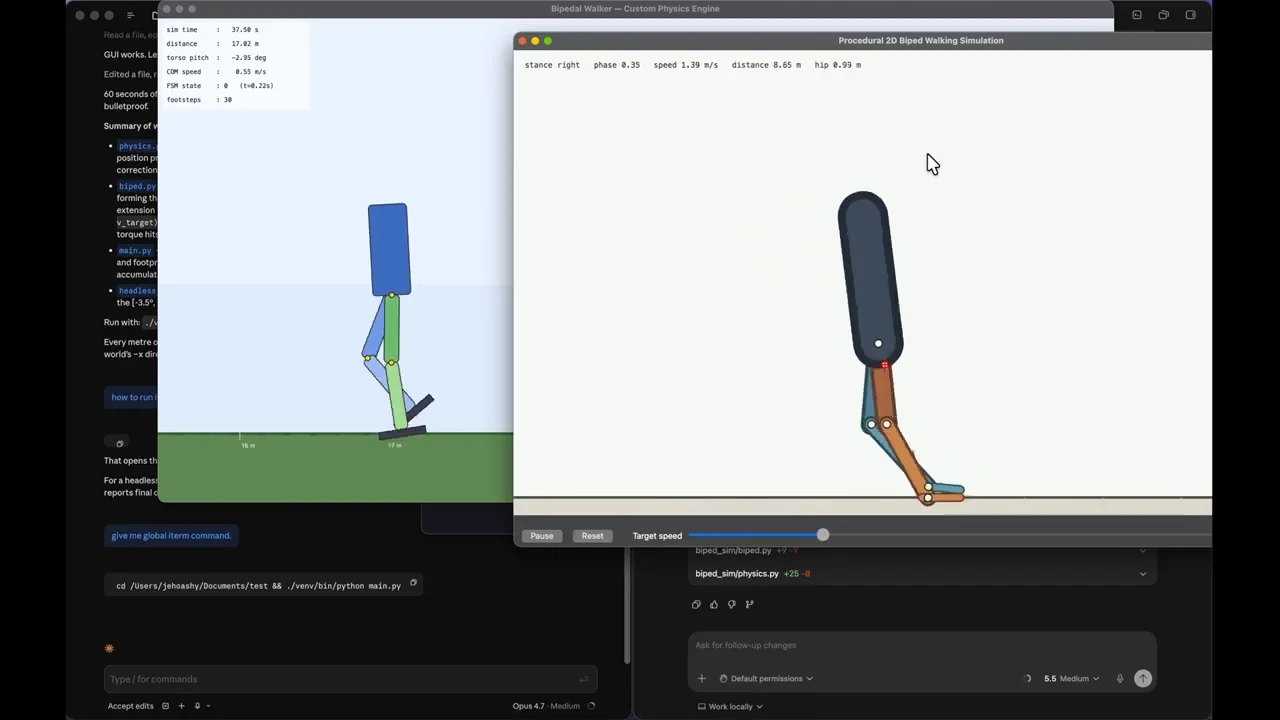
Test 8: Python Bipedal Walking Simulation▶ 46:40
This complex Python task requires simulating human walking from scratch. Opus 4.7 engages in iterative self-improvement, debugging its code internally until it produces a smooth, forward-moving gait. GPT 5.5 completes the task faster with fewer tokens but produces a less natural movement. Opus 4.7 wins for superior output quality despite higher resource usage.
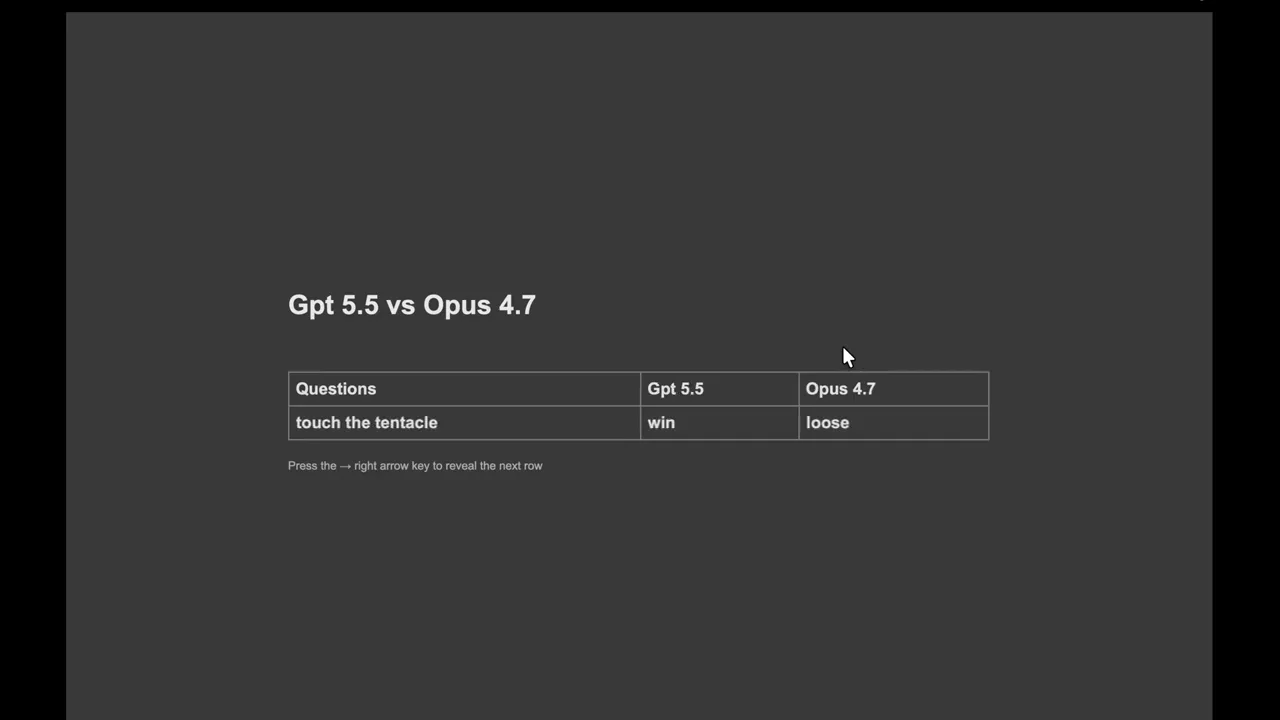
Test 9: Touch the Tentacle▶ 55:00
This navigation test involves guiding an agent through increasingly complex obstacles. GPT 5.5 successfully navigates high-complexity mazes where Opus 4.7 fails. GPT 5.5 wins for better spatial reasoning and pathfinding.
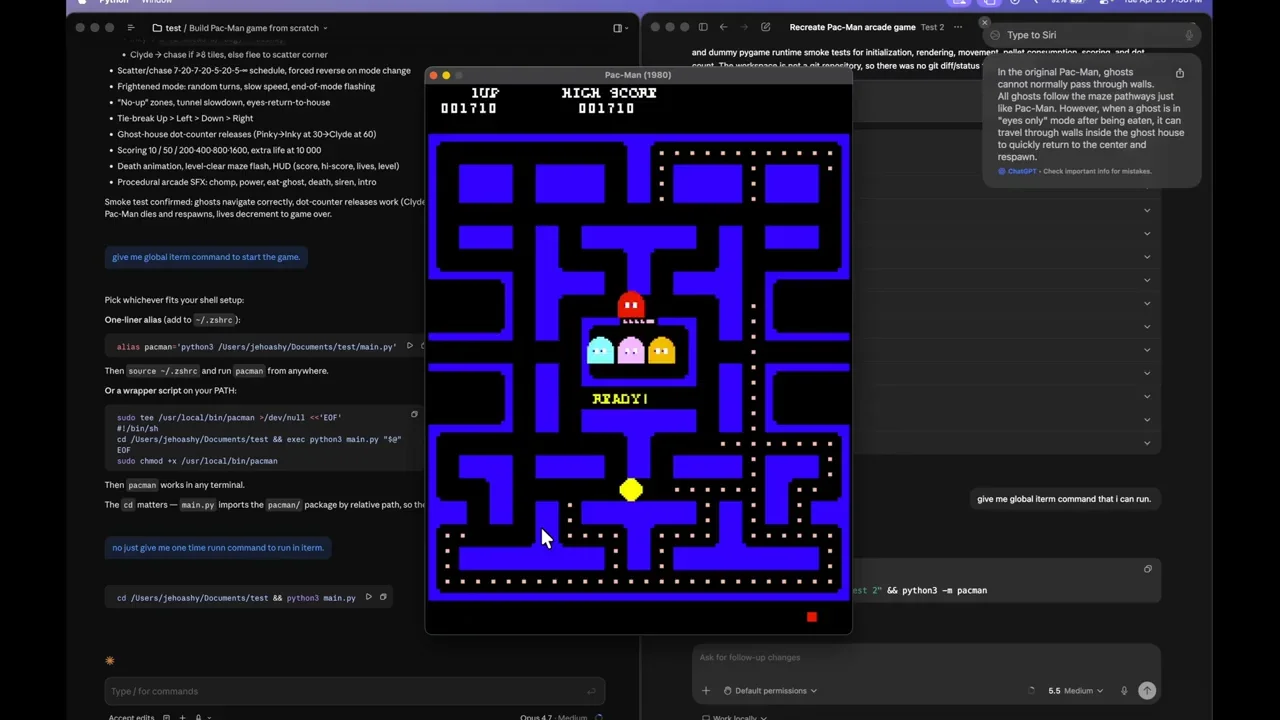
Test 10: Pac-Man Game▶ 50:00
The final test is a Pac-Man clone. Opus 4.7 creates a visually authentic game but fails on logic, allowing ghosts to pass through walls. GPT 5.5 produces a game with thinner pathways and less polished graphics, but the collision detection is correct, and ghosts cannot breach walls. GPT 5.5 wins for functional correctness.
Final Verdict▶ 55:00
Opus 4.7 scores four points in front-end tasks, demonstrating superior design aesthetics and visual fidelity. GPT 5.5 scores three points in backend and logic-heavy tasks, showing strength in physics, algorithmic complexity, and functional correctness. The total score is six points for Opus 4.7 and five for GPT 5.5.
For front-end development, design, and visual content creation, Opus 4.7 is the preferred model. For game physics, backend logic, and complex algorithmic problem-solving, GPT 5.5 is the stronger choice. The decision depends on whether the priority is visual polish or functional reliability.